
サイトを作成する中で、「このページ検索されるとまずいなー」というページが出てくることもあるのはないでしょうか?
そんなときのための、特定のページを検索されないようにする方法を調べる機会があったので、まとめておきます。
「検索されない」は「ページが見えない」わけではない
ここでいう「検索されない」は「検索エンジンにインデックスされない」、「検索エンジンに登録されない」という意味です。
Googleで検索をしたときに、検索結果に特定のページが表示されないということです。
なので、そのページのURLを知っていたり、そのページへのリンクがどこかにリンクされていればアクセスはできてしまいます。
「URLを教えた人以外には、あまりそのページを見られたくない」とか「特定のページからのリンクのみそのページにたどり着いてほしい」といったときに使えるのではないでしょうか。
特定のページを検索されないようにする方法
特定のページを検索されないようにするは、「robots.txt」を使います。
「robots.txt」
「robots.txt」は、サーバーのルート直下に配置されたファイルのことです。
ルート直下というのは、サイトURLのすぐ下ということです。このサイトで言えば、「https://mlog.xyz/robots.txt」ということです。
この「robots.txt」ファイルに検索されたくないページを記述し、サーバーのルート直下に配置するだけです。
試しに現在の「robots.txt」ファイルにアクセスしてみます。

「https://mlog.xyz/robots.txt」にアクセスしてみると、下記のように表示されると思います。

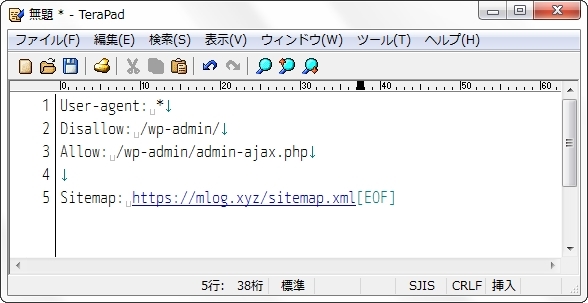
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://mlog.xyz/sitemap.xml書いてある内容としては、こんな感じです。
| User-agent | このルールを適用するクローラ。記入必須。 「*」を記述することですべてのクローラに適用。 |
| Disallow | クロールをブロックするディレクトリやページ。 「/wp-admin/」はWordPressの管理画面だから検索せさない。 |
| Allow | クロールを許可するディレクトリやページ。 |
| Sitemap | sitemap.xmlのURL。 サイトマップは「Google XML Sitemapsプラグイン等で作れます。 |
クローラ(Crawler)とは、ウェブ上の文書や画像などを周期的に取得し、自動的にデータベース化するプログラムである。「ボット(Bot)」、「スパイダー」、「ロボット」などとも呼ばれる。
クローラ – Wikipedia
このファイルの「Disallow」欄に検索されたくないページを追加で記述していけばいいのです。
「robots.txt」の更新手順
ということで、ここからやることは以下の通りです。
- サーバーから「robots.txt」をダウンロード
- 「robots.txt」に追加記述
- サーバーに「robots.txt」をアップロード
これだけです。
サーバーから「robots.txt」をダウンロード
まずはサーバーから「robots.txt」をダウンロードするわけですが、先に答えを言ってしまうと、WordPressを使ってサイトを作成している場合、サーバー内を探しても「robots.txt」ファイルを見つけることはできません。「robots.txt」ファイルは無いのです。
試しに、FTPソフトを使ってサーバー内にアクセスしてみます。
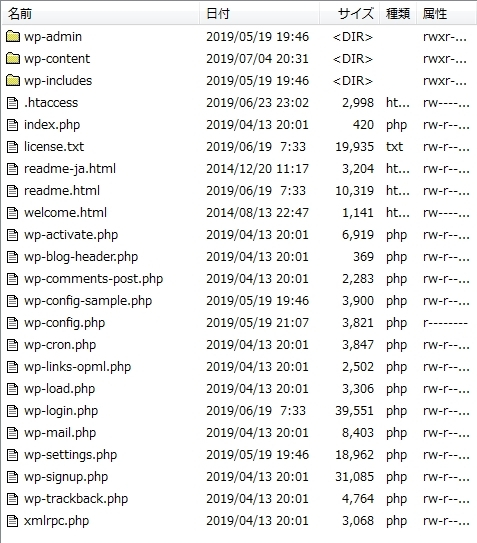
やはり、ルート直下を探してみても「robots.txt」はありません。
WordPressの「robots.txt」はどこにあるのか?
WordPressの場合、サーバー内のどこを探しても「robots.txt」は見つけられません。
でも、さっき「https://mlog.xyz/robots.txt」にアクセスしたときは、ちゃんとルート直下にありましたのよね?
これはどういうことかというと、WordPressをインストールしたときに、「仮想robots.txt」が自動で生成されるのです。
仮想なので、「robots.txt」にアクセスすることはできますが、ルート直下に「robots.txt」が物理的にあるわけではないのです。
「Disallow: /wp-admin/」とか「Allow: /wp-admin/admin-ajax.php」を記述されていたのも、WordPressをインストールしたとき、勝手に記述されたものです。
ということで、ダウンロードはできないので、新たに「robots.txt」ファイルを作成します。
「robots.txt」の作成方法
まずテキストが編集ができるソフトを起動させます。「メモ帳」とかでいいです。私は「TeraPad」を使います。
そこに自分のサイトの「/robots.txt」にアクセスし、そこに記述されているものをそのままコピーして、「TeraPad」に貼り付けします。
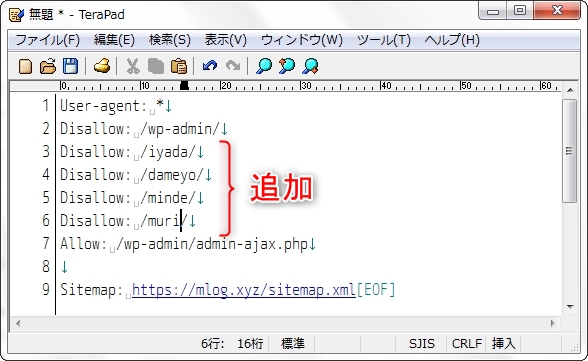
貼り付けたら、「Disallow: 」の行を増やしていき、検索されたくないページの記述をします。
WordPressならパーマリンクの部分です。僕の場合、「スラッグ」の部分でもあります。
「https://mlog.xyz/iyada/」というページを検索させたくなければ、
Disallow: /iyada/と記入します。
検索されたくないページが何個もあれば、何行も「Disallow: 」を追加していきます。
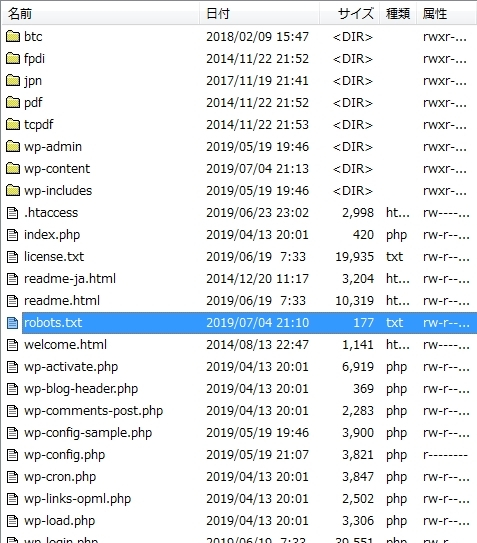
記述が終わったら保存するのですが、「robots.txt」という保存します。文字エンコードは「UTF-8」で保存します。
サーバーに「robots.txt」をアップロード
ファイルができたら、サーバーにアップロードします。
FTPソフトを使って、「robots.txt」をアップロードしましょう。
正しく「robots.txt」 が設定されているかどうかは、「Google Search Console」の「robots.txt テスター」でも確認できます。
Google Search Consol > クロール > robots.txt テスター でアクセスできます。
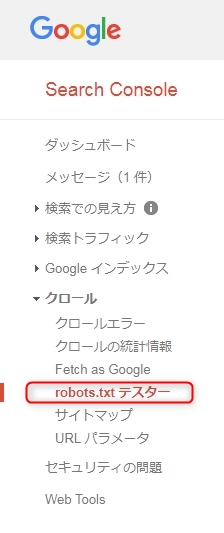
もし「robots.txt テスター」ページで、サーバーからアップロードした最新の「robots.txt」ファイルの情報が表示されていない場合は、「送信」をクリックします。
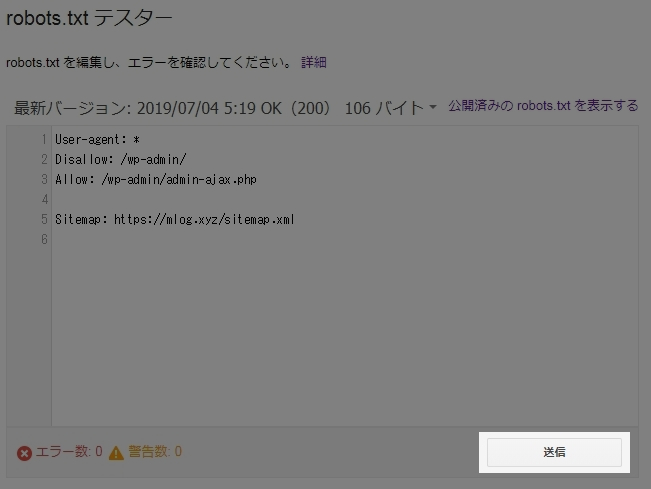
そして、「3 Google に更新をリクエスト」の「送信」をクリックします。
それから、「robots.txt テスター」ページを再読込すると最新の情報が表示されます。

その他の特定のページを検索されないようにする方法
特定のページを検索されないようにする方法は、他にもあるので紹介します。
メタタグのnoindex
検索されたくないページの<head>部分に <meta name=”robots” content=”noindex” /> と記述することでインデックスされなくなります。
ページごと直接記述しないといけないため、WordPressではあまり実用的ではないと思います。
robots.txtとnoindexの違い
robots.txtとnoindexの違いは、クローラの動きの違いです。
クローラは、クロール(WEB上を情報を収集)しているのですが、サイトの中身を見る前に「robots.txt」を見ます。そして「robots.txt」に記述されたルールに従い、クロールを禁止されたページはクロールしません。
noindexの場合、ページ内にメタタグとして記述されているわけですから、クローラはページ内をクロールしたときやっと「noindex」と記述されていることに気づきます。でも「noindex」と記述されているので、インデックスはしないというわけです。
- robots.txt → クロールすらしない
- noindex → クロールするがインデックスしない
WordPressテーマ「Cocoon」

WordPress界隈では超有名なテーマ「Cocoon」。
このテーマで、メタタグのnoindexを記述することが簡単にできます。
「Cocoon」をテーマに設定していると、 投稿画面の下に「SEO設定」が表示されます。
その中に「□インデックスしない(noindex)」というチェック項目があります。
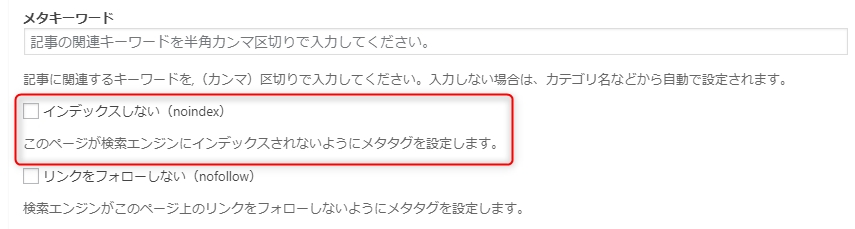
ここをチェックすると、そのページに <meta name=”robots” content=”noindex” /> が記述され、検索エンジンにインデックスされないようになります。


コメント